首先,構建一個搜索系統:電商場景的搜索
搜索引擎
搜索系統的核心是搜索引擎,目前Lucene、ElasticSearch等開源引擎已十分成熟,阿里云也提供完整的搜索解決方案-OpenSearch,包含基于Ha3的搜索引擎(Heaven ask 3)及系列管控工具。這里,我們簡單描述下搜索引擎內的基本概念作為導引,不過多深入引擎的具體實現(那將是一個冗長的話題,網絡上的資料也隨處可見)。 搜索引擎的基本概念- ? 分詞 通過一定規則對文本分出單詞,每個單詞作為搜索的最小粒度單元。只有單詞匹配,文檔才能被召回,因此分詞的準確是搜索精準的基礎。如“紅色摩托車” 被分詞成“紅色”, “摩托車”, 那它將被“摩托車”或者“紅色”召回, 如果分詞成“紅色摩托”, “車”,那它在引擎中被搜索出的概率就將大打折扣。
- ? 索引
- ? _ 紅色蘋果手機, doc1_
- ? _ 紅色蘋果, doc2_
- ? “紅色”,“蘋果” -> doc1, doc2
- ? _“手機” -> doc1 _
- ? 倒排索引 稱為反向索引、置入檔案或反向檔案,是一種索引方法。被用來存儲在全文搜索下某單詞在文檔存儲位置的映射。它是文檔檢索系統中最常用的數據結構。
- ? 正排索引 也叫attribute索引或者profile索引,是存儲doc某特定字段(正排字段)對應值的索引,用來進行過濾、統計、排序或者算分使用。正排索引中“正”指的是從doc-> fieldInfo的過程。
- ? 索引內容類型 文本索引、空間索引 、向量索引、數值索引
- ? 排序方法 匹配召回的結果集,通過特定的排序規則呈現。這里的排序規則,可以是單一維度的排序(如按價格、銷量、發布時間);人工設置的權重分;相關性得分;特定場景的模型打分等。
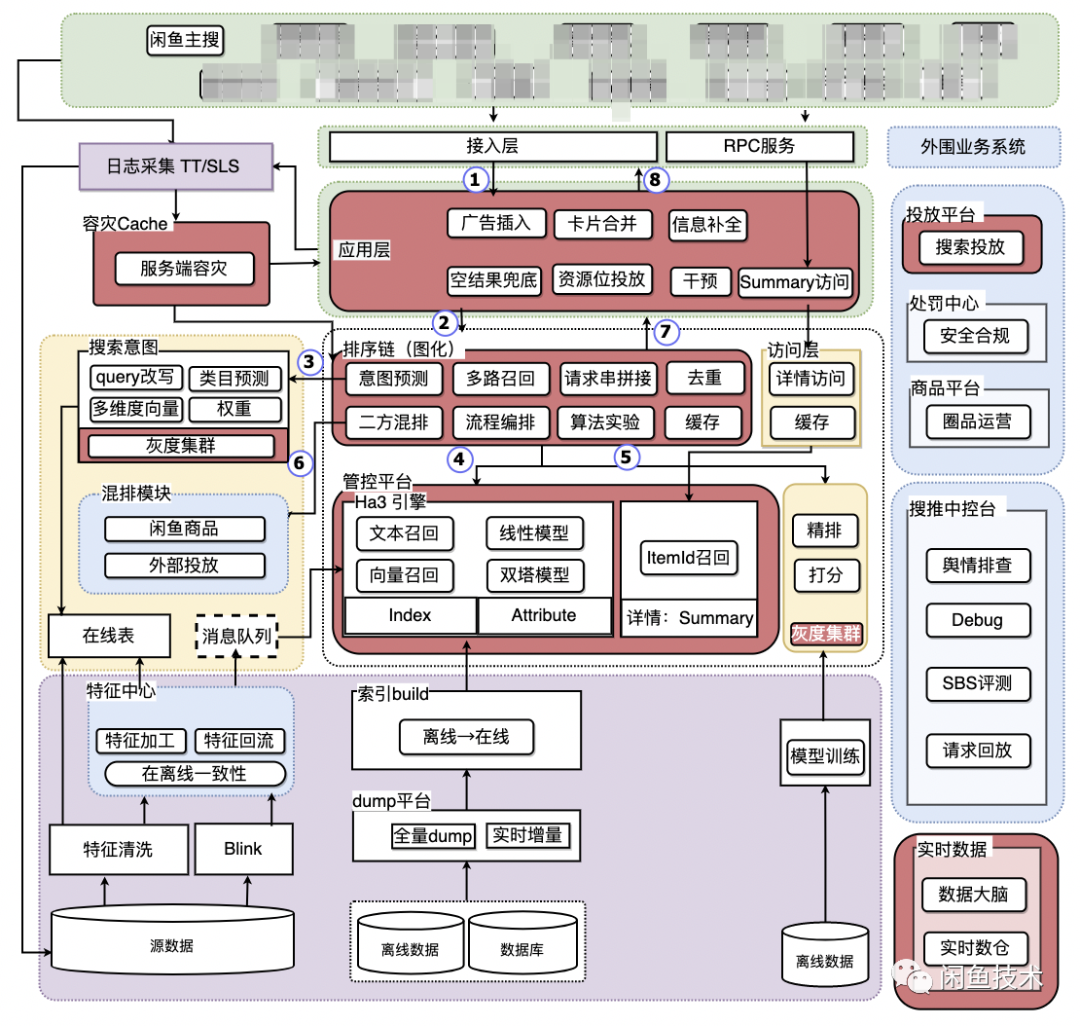

在線服務
上述架構圖中的步驟1 ~ 8為一次搜索請求的完整執行流程 1)請求接入模塊 -> 應用層 處理客戶端或h5請求,請求接入模塊的主要工作:參數校驗、負載均衡、安全攔截。大部分的非法請求在這一層被攔截,避免進入系統核心模塊后,導致不可預期的結果。應用層承載面向用戶的業務邏輯:實際處理用戶的業務請求,進行安全合規檢測,同時并行請求投放的各類資源位。 2)應用層 -> 排序接入層 排序接入層是連接應用層與底層引擎的紐帶,也是閑魚搜索系統的最核心模塊。他負責解析應用層的搜索請求,并對其進行合適流程編排:意圖預測->請求拼串->搜索引擎召回->精排模型打分->重排規則->外部混排。 3)排序接入層 -> 意圖預測模塊 負責分詞并預測搜索請求的實際意圖,包括錯詞改寫(例:平果->蘋果)、同義詞的合并(例:pingguo->蘋果),類目預測(例:“蘋果”出手機,還是出水果,它們各自的權重又是多少?)。 4)排序接入層 -> 搜索引擎 利用意圖預測得到的信息,合并應用層參數,拼裝出合法的搜索引擎請求,在搜索引擎內部歷經“海選”、“粗排” 、”精排” 三個階段,得到符合召回條件的商品集。 5)排序接入層 -> 精排模型打分 由于RT的限制,搜索引擎內部無法完成對海量商品復雜度較高的打分計算。這一步的工作,將引擎召回的商品集送入更精準的打分系統進行算分。為什么不把打分服務放在引擎內部?技術上是可行的,但由于打分服務變更頻率頻繁,而引擎相對穩定,處于系統迭代穩定性的考慮,獨立拆分精排打分服務是更好的選擇。 6)排序接入層 -> 混排模塊 部分業務場景下,合作方有合并混排的訴求。獨立拆分混排服務,隔離開發環境,讓不熟悉主搜的外部開發同學在獨立混排模塊內做開發,即使服務異常,也不至于影響閑魚本身的搜索能力。 7)排序接入層 -> 應用層 排序完成的商品列表,在應用層補充實時信息,如各類標簽,促銷信息等。同時,將商品搜索結果與廣告等各類投放組裝層最終的搜索結果頁。 8) 應用層 -> 接入層 -> 客戶端 將最終的搜索結果頁返回到客戶端或h5頁面進行渲染。離線模塊
與在線服務對應, 搜索系統的離線模塊負責數據的dump,清洗,索引構建。 搜索引擎離線模塊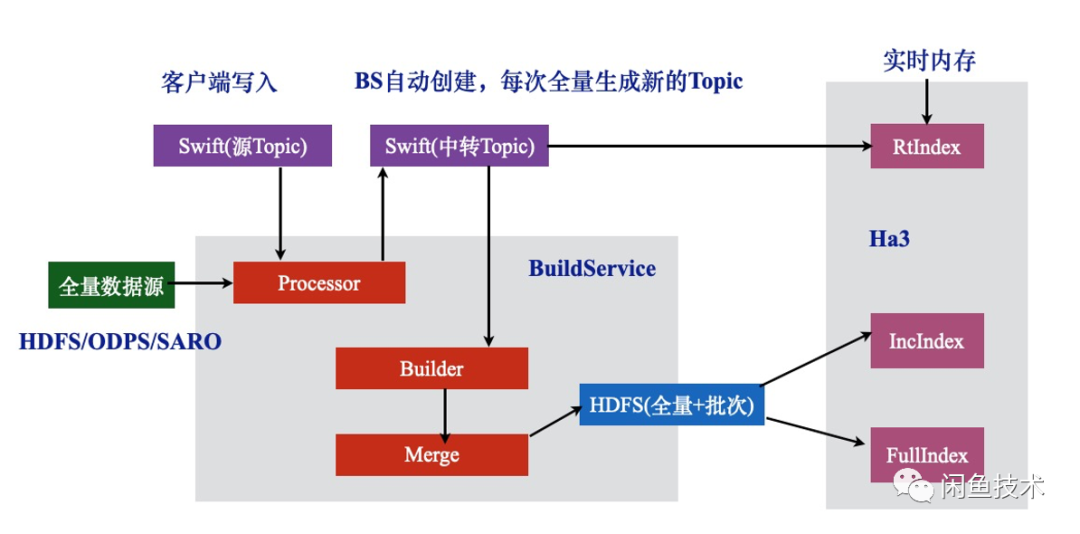
穩定性
搜索承載閑魚導購線的核心流量,因此對系統的穩定性和業務的高可用有極高的要求。閑魚搜索系統,分別在中心機房(張北)和單元機房(南通)進行了異地多機房部署,確保當單一機房故障時,流量可轉發至正常機房服務。 應用層異地多活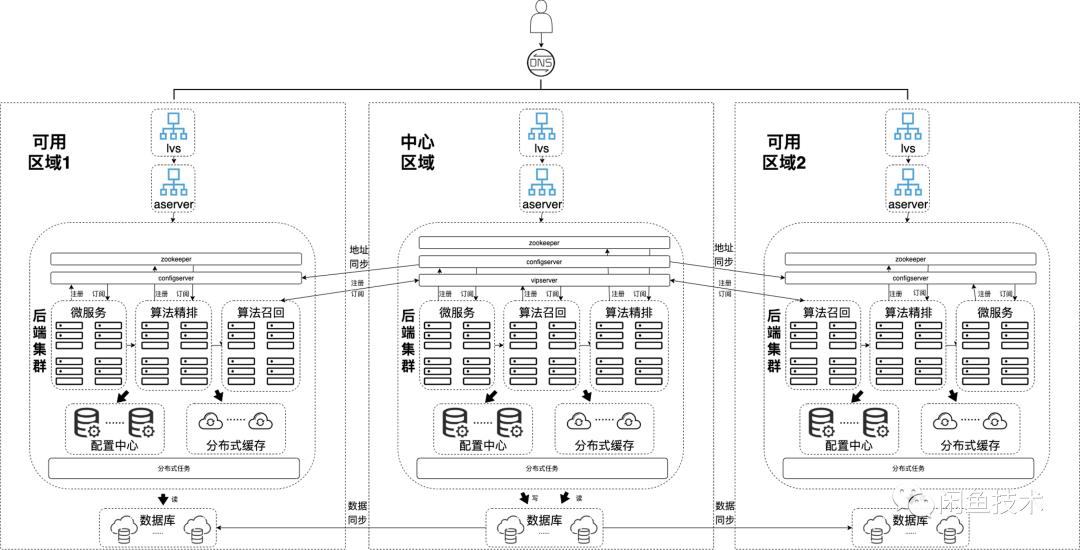
系統
核心鏈路以外,搜索業務的高效運作也離不開一系列系統。 投放系統 —— 資源位與配置的投放
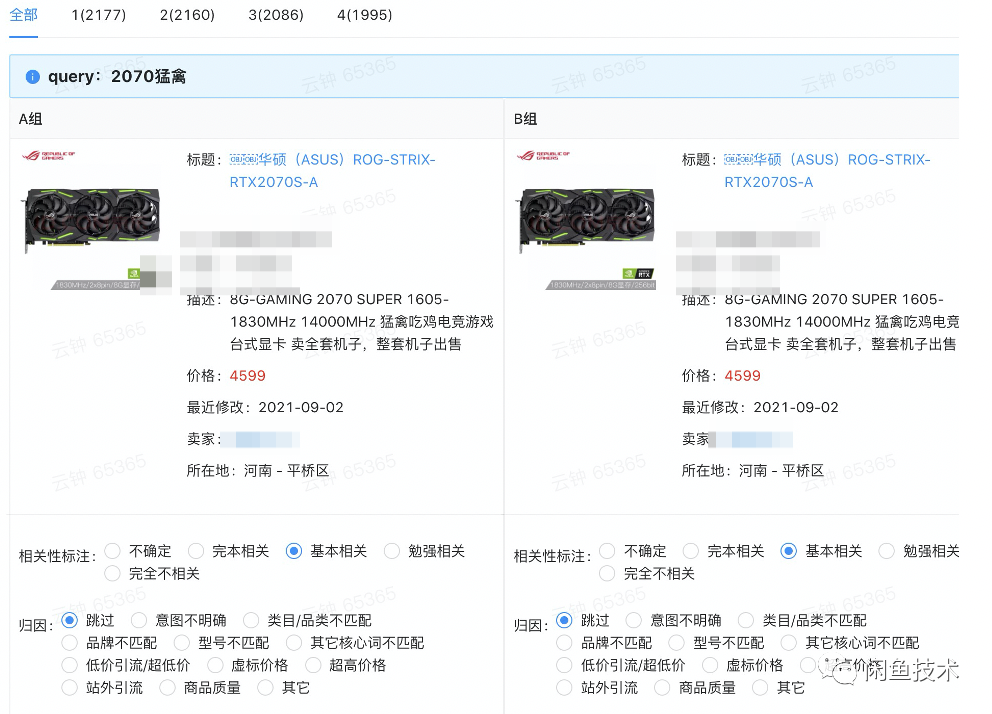
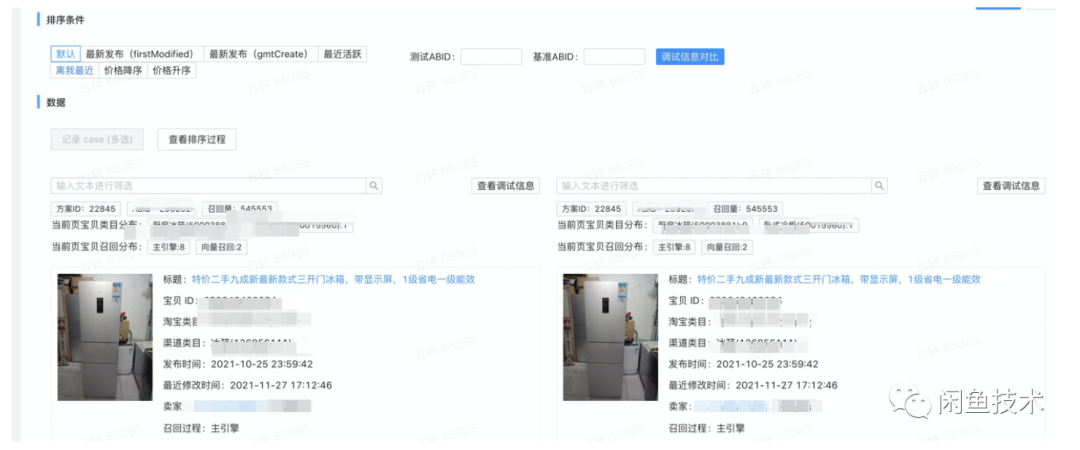
然后,優化它:閑魚搜索系統時效性優化
差異化場景
上一章節提到的搜索系統架構適用于大部分電商平臺,但閑魚搜索場景與常規電商平臺之間,又存在著顯著差異。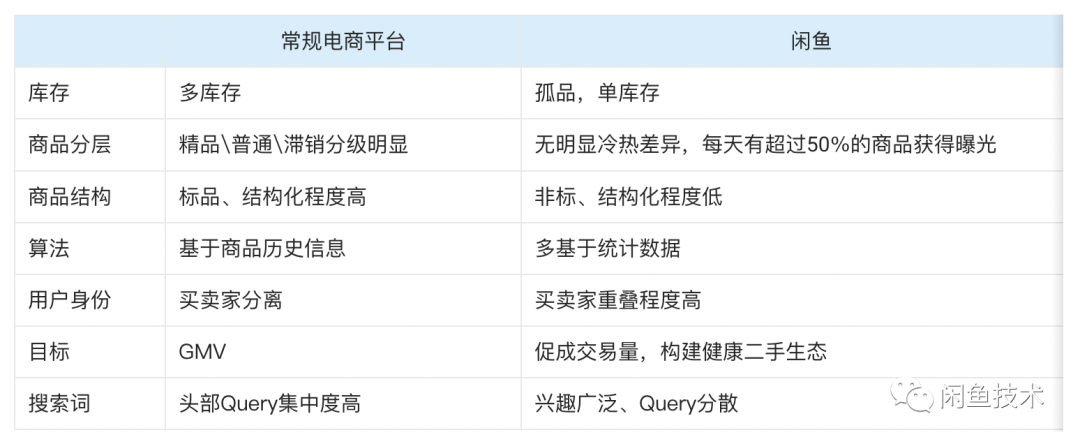
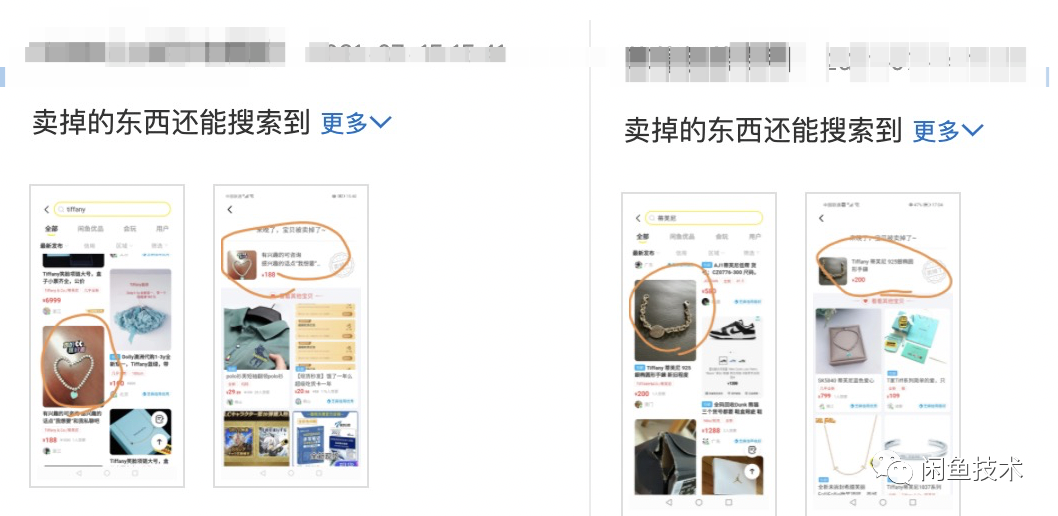
Searcher擴列
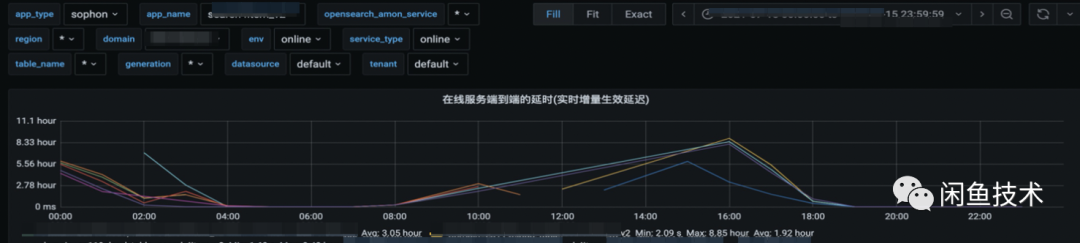
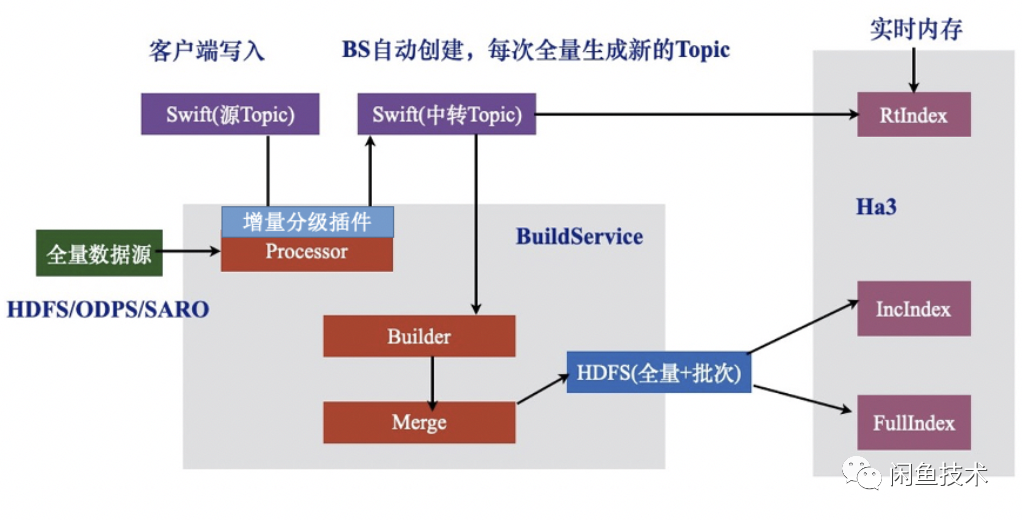
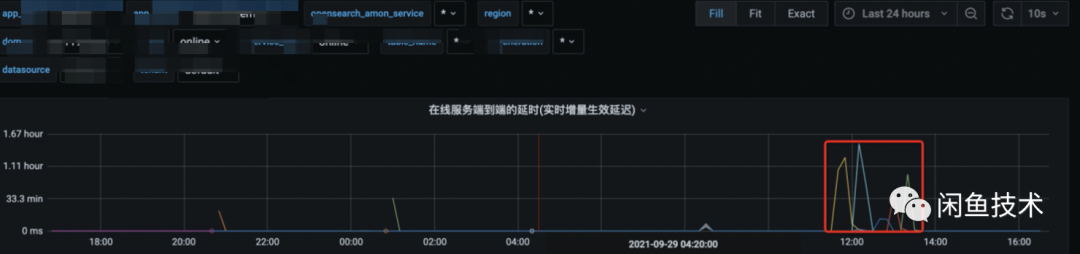
排查鏈路實時處理能力的瓶頸,如上文離線模塊中對實時增量的描述(數據產出方實時生產的數據經中轉Topic實時發送至Ha3,由Ha3引擎內的BS_lib構建出實時索引加載使用), 在實時增量到達索引所在searcher列之前都未出現延時,因此瓶頸位于在線searcher的BS_lib的消費能力, 最直接的方式是提升searcher的處理能力。因此,我們將searcher的列數從16列擴大至24列,提升了50%的實時增量處理能力,增量延時緩解。引擎架構治理
我們重新思考了閑魚主搜引擎的架構與定位 。在之前的架構中,倒排、正排、詳情字段部署在同個引擎(Ha3引擎支持這種能力)。倒排、正排用作查詢索引,詳情字段補充商品詳細信息,并對外提供信息補全服務。但查詢的請求量是極其不對等的, 詳情字段的qps為索引字段的5.3倍。倒排與正排字段的數量遠大于詳情字段, 因此查詢請求的機器要求是小CPU, 大內存,詳情請求的機器則是大CPU,小內存。兩類字段部署在同一引擎, 各自的資源短板被放大。同時,各字段實時增量是累加的。因此,我們拆分了查詢引擎 與 詳情引擎,緩解增量壓力的同時,機器資源消耗也有所降低。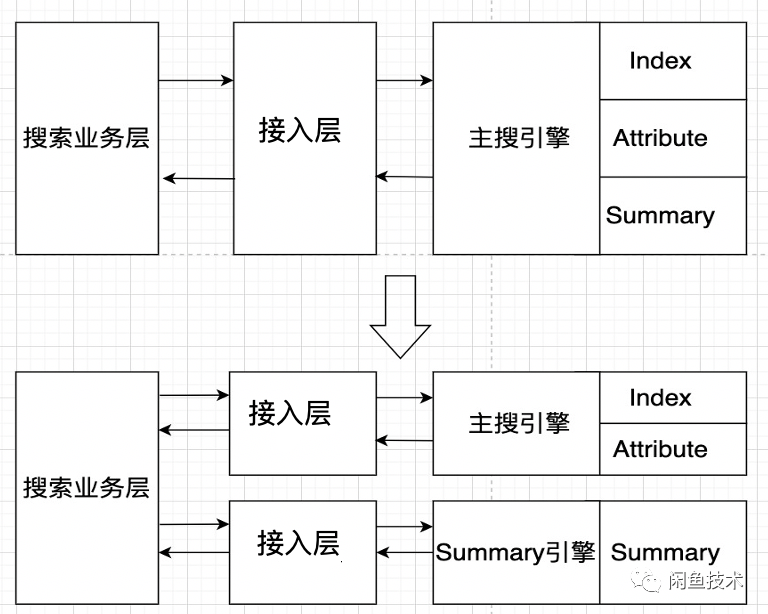
增量分級
做了以上兩個優化后, 增量延遲有所緩解,但整體的增量量級并沒有下降多少。因此在離線鏈路中,我們開發了增量Profile插件,用來統計字段修改的頻率。

輔表寫擴散問題
優化增量量級的另一個重要關注點就是輔表寫擴散問題。商品以item_id為主鍵分列部署,離線階段,當輔表有驅動增量時,跟主表join后增量翻倍增長。例:商品上掛載用戶在線狀態的特征,當用戶狀態變化時,該用戶的所有商品都會發出實時增量消息。量級將遠大于用戶在線狀態的實際消息量級。解決方式是將這一類字段,單獨改造成在線輔表, 通過在線join的方式查詢。
最后
電商平臺的搜索是一項系統性工程, 經過多年發展,已沉淀出一套通用性的框架。里面不僅包含對搜索引擎的理解,也體現服務端架構設計的可伸縮、平行擴展等概念。但僅有框架的認知還不足以支撐快節奏的互聯網業務發展。在通用框架的基礎上,深刻理解搜索業務,關注穩定性、研發效能,找到應用場景的痛點,有針對性的做出架構調整,才能構建出真正助力業務發展的搜索系統。聲明:本文由網站用戶香香發表,超夢電商平臺僅提供信息存儲服務,版權歸原作者所有。若發現本站文章存在版權問題,如發現文章、圖片等侵權行為,請聯系我們刪除。