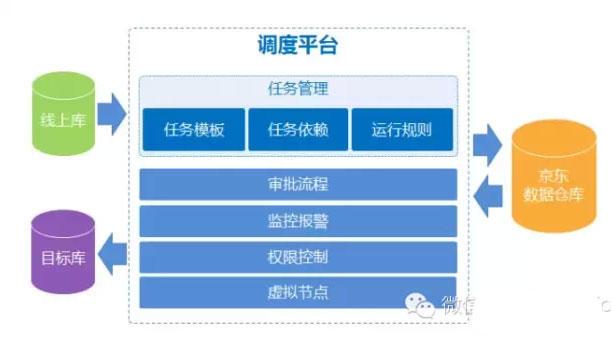
對于京東大數據平臺來說,數據產品并不是一個新鮮事物,2011年自建數據倉庫上線的同時,第一款數據產品調度平臺也一同上線并正式投入使用。
調度平臺
訂單交易,倉儲物流等眾多京東系統都會產生數據,僅日志內容每天的大小約為1TB,大量的數據如何統一匯總到數據倉庫來呢?這就需要調度產品來實現數據生產。京東調度平臺發展至今已經是3.0版本,每一次的更新迭代都凝聚著京東大數據平臺開發工程師許許多多個日夜的心血,也是我們技術突破與功能升級的具體體現。
調度平臺1.0版本架構
1.0版本于2011年8月上線,一臺服務器作為中心節點指揮調度,另外3臺服務器負責相關數據作業,任務之間通過后置變量的方式設定前后依賴關系,調度機制便運行起來了。數據倉庫建立之初的任務并不太多,數據量沒有太過龐大,數據ETL過程所需計算資源也都完全應付得來。
但隨著倉庫收納數據的增加,數據生產任務越來越多,任務之間的依賴關系也變得越來越復雜。每個BI工程師需要根據自己的生產任務設定后置變量的值以建立任務依賴關系,任務多了之后不但設置起來耗時費力且不易管理,當一個人的任務需要重跑時后置變量的修改可能會影響到別人的任務。
2.0版本上線了新的調度引擎,徹底解決了這個問題。新任務上線只需要選擇依賴的父任務即可建立關系,且流程獨立,不會因同一個任務被多個依賴而造成干擾。除此之外,任務可視化配置與瀏覽功能也在這個版本上線,任務運行狀態監控預警功能也投入使用。
這之后的功能升級也一直在進行,較大的功能改進莫過于虛擬節點了。數據生產過程中,盡管幾率很低,但仍然還是會出現一些物理節點掛掉的情況,而這種情況一旦出現,影響將會很嚴重。于是,虛擬節點的功能應運而生,原理就是在原來的物理機集群上做一層虛擬化,如果遇到生產節點故障的情況自動切換到另一個節點。同時,根據不同節點的負荷,將新的任務自動分配到負荷較小的節點,做到負載均衡。這一系列功能的上線使得平臺的穩定性大大提高。
3.0版本從功能上更加豐富,并且實現了數據生產的半自動化運行機制。所謂的半自動化是指數據任務可在配置目標數據庫、表之后自動生成ETL模板并完成數據清洗,之后是人工創建調度任務完成數據生產。另外,自主研發的抽數模塊Plumber也在這個版本中上線,Plumber技術實現了異構數據庫之間的快速數據交換,且具有較高的穩定性,數據導入導出的維護成本也大大降低。還有服務器運行狀態的監控系統Phenix也集成到了調度監控中,實時采集服務器運行狀態數據并對服務器心跳、存儲空間使用、CPU資源消耗等進行預警。
對于上游系統故障造成的歷史數據補充問題,之前的版本中需要人工查找相關依賴任務,然后一個一個配置參數后點擊重跑,而在新的版本中BI工程師們期待已久的一鍵重跑功能上線了,并且支持批量操作。一千多個重跑任務,BI工程師加班到半夜一個一個點鼠標的日子永遠成為了過去。
作為大數據平臺的核心系統,調度平臺不僅承擔著數據生產的重要使命,同時也負責集市數據推送,模型數據加工等任務,部門有超過三分之一的人都在圍著它轉,重要性可想而知。今后的功能升級迭代將在增強生產能力的同時更加注重自動化服務及開放運營等平臺產品的特性,為大數據管理及挖掘大數據價值提供可靠保障。
在此我向大家推薦一個大數據開發交流圈:658558542 里面整理了一大份學習資料,全都是些干貨,包括大數據技術入門,大數據離線處理、數據實時處理、Hadoop 、Spark、Flink、推薦系統算法以及源碼解析等,送給每一位大數據小伙伴,讓自學更輕松。這里不止是小白聚集地,還有大牛在線解答!歡迎初學和進階中的小伙伴一起進群學習交流,共同進步!
數據集成開發平臺
數據集成開發平臺是京東大數據發展的一個里程碑產品,它的出現結束了數據分析師和業務部門數據需求人員通過客戶端工具手工提取數據的痛苦經歷,并對后來的數據知識管理平臺等產品的出現產生直接影響。當前平臺用戶接近1000人,數據訂閱任務總量逾4萬個。
早期版本的數據集成開發平臺就是命名為提數工具,提數也是當時寄予這款產品的最重要的期望。相信每一家公司對于數據的需求都是“剛需”,快速發展的京東,流動并且快速流動的數據更是像一個人身體里的血液一樣不可或缺。所以數據分析師總是最繁忙的,每到月初需要支持財務經營分析的人員提取數據時,還要拉上不少工程師共同參與這場提數大戰。在前后臺數據部合并后最瘋狂的日子里,數據部還曾出現過“全員提數”的場景。
在這樣的背景下,數據集成開發平臺的1.0版本誕生了。這是一款查詢數據并且支持周期性數據訂閱的產品,同時打通了京東私有云服務Jbox,可以供已授權人員安全、便捷的查詢和提取數據,尤其對于需要定期提取大量數據做分析的人員(如財務經營分析同事)有很大幫助。
功能上來講,通過Web端在線數據查詢和數據訂閱是兩大主要功能,同時,SQL編寫界面還支持元數據信息的查看,并且可以在線保存編輯中的代碼,這給提數人員帶來很大便利。底層接入的數據庫包括當時存在的SQLServer、MySQL和Hive,SQL語法上根據不同的數據庫類型選擇不同的語法即可,其它執行邏輯都是一樣的。
在采用Extjs的前端頁面偶爾存在一些滾動條失靈的小Bug,這給用戶體驗上帶來一定影響。另外,雖然Extjs強大的表單功能成就了集成開發平臺這樣的富客戶端應用,但是其UI風格的局限性也是非常明顯的。隨著后期產品線的豐富,新推出的產品已經棄用Extjs,轉而采用Bootstrap前端,從2014年7月份,采用新的前端技術,數據集成開發平臺與后期推出的數據知識管理及數據質量監控產品融合后統一在一個系統上線。
數據知識管理平臺
數據知識管理平臺產品的出現是個水到渠成的結果,在數據倉庫模型規范確定之后,元數據信息也有了標準的分類體系。按照標準的分類體系將元數據信息分門別類管理起來,同時提供內容搜索、類Wiki的編輯維護以及咨詢評論功能,數據知識管理平臺就呈現在大家面前了。后期版本升級過程中又提供了維度表的維護功能,給模型開發維護的同事帶來很大便利。
京東分析師
Apricot(杏子)、Blueberry(藍莓)、Cloudberry(云莓),水果連連看?不,這是報表展現平臺三個版本命名的代號,也是產品域名的首段字符串,首字母分別是ABC也代表了產品演進的過程。當前版本代號為Cloudberry,產品正式名稱為京東分析師,毫無疑問,我們賦予這款產品的除了基本的數據可視化能力,還有數據分析的能力。
體驗過Tableau的用戶都會被其靈活的控制臺和美妙絕倫的圖表展現所征服。我們所做的就是在Web系統中盡可能的實現Tableau桌面系統所能達到的效果,并且在產品服務能力上更加強調自助服務的智能軟件分析平臺。
技術架構上,京東分析師前端自主開發可自定義的展現布局,封裝了豐富的圖表展現組件,后端報表配置系統支持MySQL、SQLServer、Oracle、API及Hive等作為數據源,并支持在線接入。交互方面,報表收藏、基于圖表的條件過濾、數據排序、深度鉆取是其基本功能,自定義報表頁面還提供郵件推送報表的功能,當某個報表數據比較重要,系統可通過郵件的形式定期發送報表供查閱。對于自己權限范圍內可瀏覽的表,系統還可根據瀏覽記錄將經常查看的表排在靠前的位置以提升體驗。
數據挖掘平臺
大數據的數據挖掘與傳統意義上的處理方法存在很大區別,京東數據挖掘平臺產品定位于構建一站式的數據挖掘算法平臺,在基礎的機器學習算法之上,可根據具體實際業務開發訂制算法,滿足算法應用場景。這一產品主要利用分布式計算,采取適用于機器學習算法的計算模型進行迭代,以解決大數據量的算法處理問題。平臺封裝的Cross Validation(交叉檢驗)、Grid Search(網格搜索)等基本數據挖掘流程給數據挖掘人員提供簡單、易用的挖掘工具。
為減少數據實體化的開銷,挖掘平臺采用基于內存的存儲引擎,集群資源調度與管理基于HadoopYarn框架,保證了集群計算性能的高可利用性和高可擴展性。平臺自2014年年中正式推出后,已經開始為廣告系統、推薦系統等提供個性化的數據挖掘算法服務。
數據質量監控平臺
數據的及時性、準確性和完整性關系到一系列數據應用的效果,大數據平臺建設之初便已著手實施數據治理的相關工作,統一數據計算口徑,設置數據校驗規則,以保證數據質量。數據倉庫升級之后,對于數據質量的關注程度更高,于是便從產品層面進行管理。從數據生產過程來看,數據質量監控平臺的基本功能包括數據生產過程中的質量檢驗、數據入庫后的質量評估以及全部生產日志的掃描存檔并生成數據質量分析報告。
數據生產過程中的質量監控主要對數據生產中源表結構的變化、字段信息的一致性進行規則校驗,并依據校驗結果進行質量評估,對存在質量問題的數據將進行自動重跑并通知后續依賴任務。入庫之后的數據將進行具體到字段粒度的數據檢查,可以對枚舉值、字段類型,甚至數值型字段的最大最小值及均值等進行規則校驗,以確定數據是否在合理的范圍內變化。
感謝您的觀看,如有不足之處,歡迎批評指正。 聲明:本文由網站用戶香香發表,超夢電商平臺僅提供信息存儲服務,版權歸原作者所有。若發現本站文章存在版權問題,如發現文章、圖片等侵權行為,請聯系我們刪除。